AWS DynamoDB
DynamoDB คือ NoSQL Database
ซึ่งเก็บข้อมูลลง SSD Storage และ 3 geographically หรือป้องกันการ single-point of failure เมื่อ data center ไหนมีปัญหาขึ้นมานั้นเอง
DynamoDB ประกอบด้วย
- Tables
- Items (row)
- Attributes (column)
- Supports Key (Primary, Composite Key)

จากรูปข้างบนนี้คือตัวอย่างของ Core components
- Table คือ People
- Item คือ Person ที่อยู่ในนั้น
- Attribute คือ item attribute ต่างๆเช่น LastName, FirstName, Address, etc.
- Key คือ PersonId ที่ทําหน้าที่เป็น Partition Key (Unique Attribute)
อย่าลืมว่ามันเป็น Schemealess ดังนั้นมันเลยมี attribute โผล่มาเต็มไปหมดไปเหมือนกันในแต่ละ items นั้นเอง และ สังเกตุบาง attribute นะ มันจะมี nested attribute แบบเจ้า Address attribute ซึ่ง DynamoDB รองรับได้ถึง 32 levels nested attribute เลยละ
Primary Key
ประกอบด้วย 2 Key
- Partition Key (Primary key หรือเรียกว่า Unique attribute)
ซึ่งเจ้า Dynamodb ใช้ partition key ในการทํา hash function เพื่อระบุที่เก็บข้อมูลบนเครื่อง Physical โดยใน Table ต้องไม่มี Partition ซํ้ากัน - Composite Key (Partition Key + Sort Key)
เป็นการรวมกันของ Partition Key ซึ่ง Unique กับ Sort Key (เช่น timestamp) จะทําให้เราสามารถ reference ไปที่ Unique Key ได้
จงจําไว้เลยว่า DynamoDB มัน Schemaless เพราะฉะนั้นเวลาสร้าง Table ด้วย Cloudformation หรือ AWS SDK เราไม่ต้องกําหนดทุก Attribute เราเลือกเฉพาะ Key Attribute สําหรับ Partition Key (HASH) และ Sort Key (RANGE) ก็พอไม่งั้นจะเกิด Error เรื่อง attribute ไม่ตรงกับ key schema นั้นเอง
Secondary Index
เป็น concept ที่ช่วยทําให้เรา queries ได้เร็วมากขึ้น(Speed Up) โดยการเพิ่มข้อมูลที่ตัวบ่งชี้ว่ามันคืออะไร (Index) เข้าไป และเราก็ทําการ search ด้วย Index นั้น โดย DynamoDB มี Index 2 แบบคือ
- Local Secondary Index (มีได้มากสุด 5 index)
ถูกสร้างเมื่อตอนเราสร้าง table เท่านั้น โดยเมื่อสร้างแล้วเราจะไม่สามารถแก้ไข โดยใช้ Partition Key เหมือนกันแต่คนละ Sort key - Global Secondary Index (มีได้มากสุด 20 indexes)
แต่ถ้าเป็น Global เราจะสร้างเมื่อไรก็ได้ โดยเราไม่จําเป็นต้องใช้ Partition Key หรือ Sort Key ก็ได้ ซึ่งจะยืดหยุ่นกว่า Local มาก
ที่ใช้คําว่า Global เพราะว่าเวลาเราสร้างแล้วมันจะสามารถเรียกใช้ได้ทั้ง base table

ตัวอย่างการใช้งาน Second Index ชื่อ GenereAlbumTitle โดยใช้ Genere เป็น Partition key และใช้ AlbumTitle เป็น Sort Key
ต่อจากข้างบนเรื่อง define Attribute แต่ถ้าเราจะทํา GSI เราสามารถประกาศ Attibute เกินได้ เพราะเราต้องเอามาทําเป็น Key Schema ของ GSI นั้นเอง
Query vs Scan
Query คือการหา items ที่เราต้องการผ่านจากการหา Key เพราะว่ามัน Unique value หรือจะใช้ Sort Key name เป็นตัวช่วยในการเพิ่มประสิทธิ์ภาพในการ Query เช่น หา User “x” activity ที่ทําใน 7 วันล่าสุด
Scan คือการหา item ทั้งหมดใน table โดยไม่สนใจ Key(s) เลยซึ่งจะได้ผลลัพธ์ที่ช้ากว่าแน่นอน เพราะมันต้อง dump ข้อมูลทั้ง table แล้ว filter ออกทีละตัว (ถ้าต้องการ) ดังนั้นยิ่ง table ใหญ่ยิ่งช้า และ Scan ไม่รองรับการทํา Ordering นะ ซึ่งถูกแล้วเพราะมัน scan ทั้ง table มีทั้ง Parallel scan อีกด้วย มันจึงไม่ได้เหมาะกับการ order
เทคนิคที่เพิ่ม Performance คือการ set page size ของข้อมูลให้น้อยลง หรือ ตั้ง scans ให้ใช้แบบ Parallel scan จะเร็วกว่า แต่ข้อแนะนําคือให้ใช้ Query แทน
Read Consistency Models
- Eventual Consistent Reads (Default)
เพื่อ performance ที่ดีกว่า การเลือกโหมดนี้จะทําให้เราได้ข้อมูลที่ไม่ delay ไม่ต้องรอ replicate ข้อมูลทุก server ก่อน เพราะฉะนั้น application ที่เลือกใช้วิธีนี้ต้องไม่ใช่ critical system เช่น booking นั้นเอง - Strongly Consistent Read
เราจะสามารถอ่านได้เมื่อทั้ง 3 geographically ของเราได้ทําการ replicate ข้อมูลทั้งหมด เหมาะกับ application ที่ critical เรื่องของข้อมูลมาก
Write Models
โดย default แล้ว การ Write ของ DynamoDB จะเป็น unconditional ซึ่งความหมายอีกอย่างคือ ใครก็สามารถอัพเดตแล้วทับ Key นั้นๆได้

ทีนี้จะเห็นว่าสิ่งที่ Alice Update ไปจาก Price 10 เป็น 8 จะถูกแทนที่ด้วย 12 ของ Bob ไปแล้ว การจะกันสิ่งนี้ได้คือต้องใส่ Conditional Expression เข้าไปด้วย เพื่อให้เวลาการเช็คค่าก่อน Update ว่า Price ยังไม่ได้เปลี่ยนไป ตามรูปข้างล่าง
เพื่อเป็นการ Write แบบ consistency นั้นเอง

Locking Model
Dynamodb ใช้ Optimistic Locking ด้วยเลข Version เพื่อใช้ในการยืนยันว่า item ที่เรากําลังจะ Update หรือ Delete เป็นของที่เราต้องการจริงๆ
ในการ Lock ของ Database หลักๆมีสองแบบ
- Pessimistic Locking
Lock การใช้งานไปเลย จนกว่าจะทํางานเสร็จ แต่อาจจะเกิดปัญหาของการ DeadLock ใน Database ได้ - Optimistic Locking
เป็นเทคนิคที่ช่วยให้เรามั่นใจได้ว่าเวลาที่เราจะ update หรือ delete item จะเป็น item เดียวกันใน Amazon DynamoDB จริงๆ โดยการเช็ค attribute ที่ทําหน้าที่เหมือนเลข version โดยเราจะสามารถ update/delete ก็ต่อเมื่อเลข version บน Server-side ไม่ได้เปลี่ยนแปลง เป็นเลขเดียวกัน (ช่วยป้องกันไม่ให้เรา overwriting ทับกับอันอื่น)
ซึ่ง DynamoDB ใช้อันนี้ใน Java SDK
Dynamo Provisioned Throughput
เป็นการวัด Capacity Units ในการทํางานของ DynamoDB มีสองส่วนคือ
- Read Capacity Unit
- Write Capacity Unit
ซึ่งมันเป็นสิ่งที่เราต้องกําหนดเมื่อสร้าง Table ว่าเราจะมีให้อย่างละกี่ตัว โดยความสามารถอ่านและเขียนจะแตกต่างกัน
- Read Capacity Unit จะถูกแบ่งออกเป็น 2 แบบตาม Read Consistency Models ซึ่งก็คือ Strongly Consistent Read of 4 KB/second *1 แต่ถ้าเป็น Eventually Consistent Reads of 4 KB/second * 2
- Write Capacity Unit จะเป็น Write Capacity 1 KB/ second * 1
ดังนั้นถ้าเรามี 5 Read Capacity Units และ 5 Write Capacity Units
ความสามารถในการอ่านของเราในโหมด Strongly Consistent Read จะเท่ากับ 5 * 4 = 20KB/second และถ้าใช้โหมด Eventually Consistent Reads จะเท่ากับ 5 * 4 * 2 = 40 KB/second ส่วนความสามารถในการเขียนจะเป็น 5 * 1 = 5KB/second นั้นเอง
ทีนี้สมมุติถ้าเราต้องการจะประเมิณ Capacity Units ในงานจริงกันโดยมีโจทย์ว่า
- ใช้ Strongly Consistent Reads
- เราต้องการให้มันอ่าน 80 items / s
- แต่ละ item มีขนาดประมาณ 3KB
อย่างที่เรารู้คือ Read Capacity Units อยู่ที่ 4KB ส่วน item อยู๋ที่ 3KB ดังนั้น 3/4 = 0.75KB และปรับให้เป็นจํานวนเต็มคือ 1 * Read Capacity Unit ต่อการอ่านต่อครั้ง
หลังจากนั้นเรารู้แล้วว่าอ่าน 1 item ต้องใช้ 1 Read Unit ทีนี้ต้องการอ่าน 80 items ต่อวินาทีก็คือ คูณเข้าไป 1*80 = 80 Read Capacity Units ที่ต้องการนั้นเอง
แต่ถ้าเราต้องการเปลี่ยนโหมดเป็น Eventually Consistent Read ก็จะใช้วิธีคิดแบบเดียวกันเลย เพียงแต่ว่าท่ต้องจําไว้คือด้วยโหมด Eventually Consistent Read มันจะเป็น Double Throughput ในการจัดการ แปลว่า 80 Read Capacity Units /2 = 40 Read Capacity Units นั้นเอง
ด้วยวิธีนี้เราก็จะมองออกว่าต้องใช้ Read — Write Capacity ขนาดไหนนั้นเองซึ่งจะเป็น Cost ของเราด้วย
เพียงแต่เมื่อปี 2018 AWS ได้ออก Pricing Model ใหม่ของ DynamoDB ออกมาเป็น On-Demand! แปลว่าเราไม่ต้องกําหนด capacity แล้ว สิ่งที่ทําคือ scale up-down ให้เองนั้นเอง เหมาะมากกับ unpredictable workload นั้นเอง (pay-per-use model) ซึ่งเอาไปใช้กับพวก serverless อย่าง lambda จะดีมาก
Provisioned Throughput Exceed Exception
สิ่งที่ต้องรู้คือมันมีเทคนิค Exponential Backoff เพื่อป้องกันการเกิด Exception ของ ProvisionedThrouhtputExceededException
Exponential Backoff คือเทคนิคที่ AWS SDK ใส่ไว้เพื่อใช้ในการป้องกัน request เยอะเกินไปแล้วเกิด exception ข้างบนขึ้น โดยมันจะทําการ รอเพื่อ retries โดยเพิ่มเวลาขึ้นไปเรื่อยๆๆ เช่น 50 ms, 100 ms, 200ms ไปเรื่อยๆ ถ้าครบ 1 นาทีแล้วยังทํางานไม่ได้ มันจะ throw exception ข้างบนออกมา (request มันเยอะไปจริงๆ)
จริงๆเทคนิคนี้ใส่ไว้ทุก AWS SDK เช่น S3 buckets, CloudFormation, SES, etc.
Transaction
ACID Transaction (Atomic, Consistent, Isolated, Durable) เป็นทฤษฐีที่ใช้กับ Database ในแต่ละ Transaction ซึ่ง
- Atomic คือ transaction ต้องถูกทํางานให้เสร็จเรียบร้อย ไม่ใช้ทําแค่ส่วนเดียวแล้วหยุดขาดจากกัน all or nothing นั้นเอง
- Consistent คือ transaction ต้อง valid ต้องถูกต้องไม่ทําให้ database พังได้
- Isolated คือ transaction ต้องแยกขาดจากกันไม่อ้างอิงใดๆกับ transaction อื่นๆ
- Durable คือ transaction ต้องยังสามารถที่จะ write to disk ได้ถึงแม้จะเกิด failure อะไรก็ตามที
DynamoDB Streams
มันคือ Time-ordered sequence ของข้อมูล DynamoDB ที่เกิดจาก insert, update, delete โดยที่ Log ของ DynamoDB Stream จะถูกเก็บไว้เป็นเวลา 24 ชั่วโมงเท่านั้น
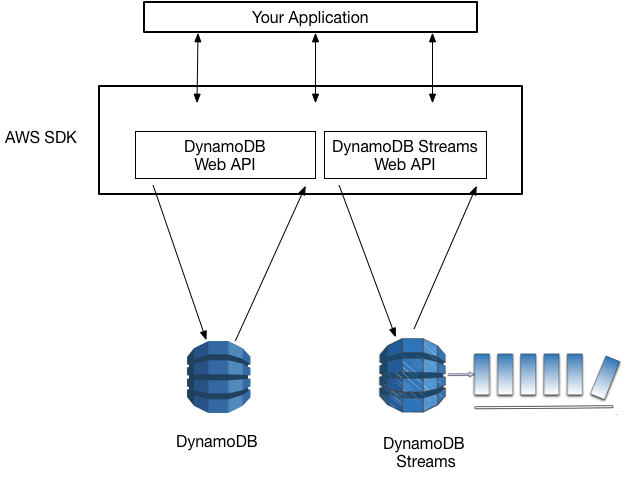
สําหรับ streams เราสามารถสร้าง event source ให้กับ lambda เอาไปใช้อะไรบางอย่างได้เหมือนกัน ซึ่งมีประโยชน์เมื่อเอาไว้เช็คจาก Logs ได้ เช่น User A จ่ายบิลสําเร็จ แล้วมันไป trigger ส่ง SNS ด้วย lambda

Access Control
จัดการด้วย AWS IAM ทั้งหมด (ซึ่งหมายถึงคุมด้วย Policy นั้นเอง)
โดยเราสามารถนํา IAM role ไปผูกกับ Items ใด Item นึงได้ด้วย เพื่อให้มีสิทธิ์เท่าที่เราต้องการจะให้ โดยเพิ่ม Condition เข้าไปใน IAM Policy (dynamodb:LeadingKeys) ให้ match Partition Key นั้นๆๆๆ
DynamoDB Accelerator (DAX)
เป็นการทํา Caching (in0memory cache) เพื่อใช้งานสําหรับ Read performance ซึ่งการันตีว่าจะเร็วขึ้นถึง 10x จากเดิม เหมาะกับ application read หนักๆๆนั้นเอง เช่น ช่วงจัดโปรโมชั่นหนักๆๆ
DAX ทํางานโดยการ write ผ่าน caching service เช่นเรา update/modify DynamoDB มันจะเข้า DAX เอง โดยเฉพาะเวลาเรา query DynamoDB มันจะวิ่งไปที่ DAX ก่อน ซึ่งถ้าไม่มีใน DAX มันจะทําการดึง item จาก DynamoDB แล้ว write ลง DAX
DAX ทํางานแบบ Eventually Consistent GetItem DynamoDB เพราะฉะนั้นมันเหมาะกับ Strongly Consistent reads มากๆ เพราะว่ามันจะได้ผลลัพธ์ที่แน่นอน
สรุป DAX นี้เหมาะกับ Readintensive application มากกว่า Write








